Stream ciphers #
A stream cipher is a function that takes
- a key \( k \)
- a nonce \( n \)
Note on notation: a set raised to an asterisk ( * ) the strings 0 or more length that can be made from the set items.
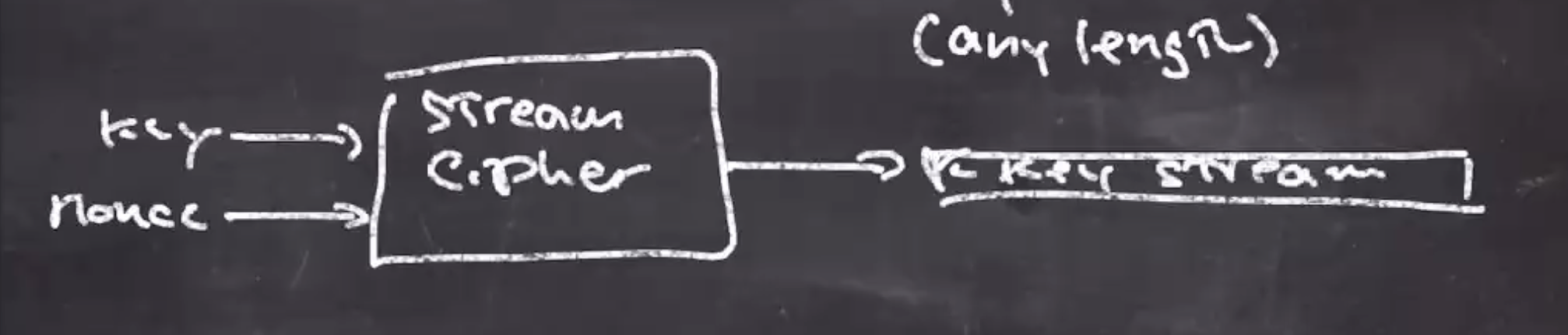
Our ciphertext is acquired via
\[\begin{aligned} \text{ciphertext} = \text{plaintext } \oplus \text{ key stream} \end{aligned}\]and plaintext (when decrypting) is obtained via
\[\begin{aligned} \text{plaintext} = \text{ciphertext } \oplus \text{ key stream} \end{aligned}\]CHACHA20 #
The most popular stream cipher.
OpenSSL ciphersuites
Note that the top 3 used ciphersuites are either AES or CHACHA20
CHACHA20 is a stream cipher (AES is a block cipher).
The CHACHA permutation takes in 64 bytes and produces 64 bytes.
The 64 byte block is the concatentation of
16B constant || 32B key || 8B nonce || 8B counter
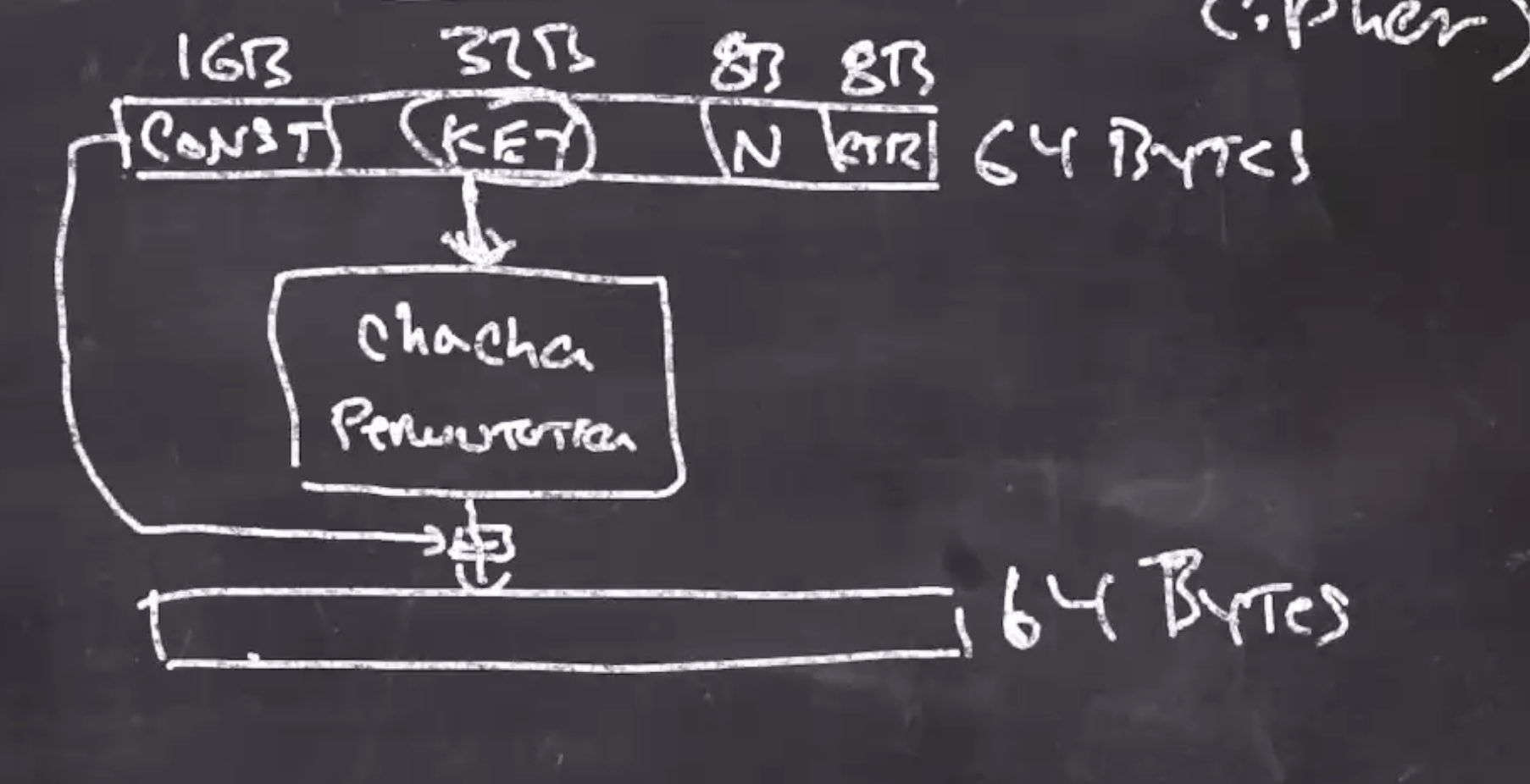
The entire block is added to the output of the permutation. The counter will continue to increment on each iteration of 64 bytes. The constant is added so that a 0 input doesn’t lead to a 0 output.
Note, CTR and OFB are stream ciphers
SIMD – single instruction multiple data #
Recall that our perm384 takes 12 uint32_ts,
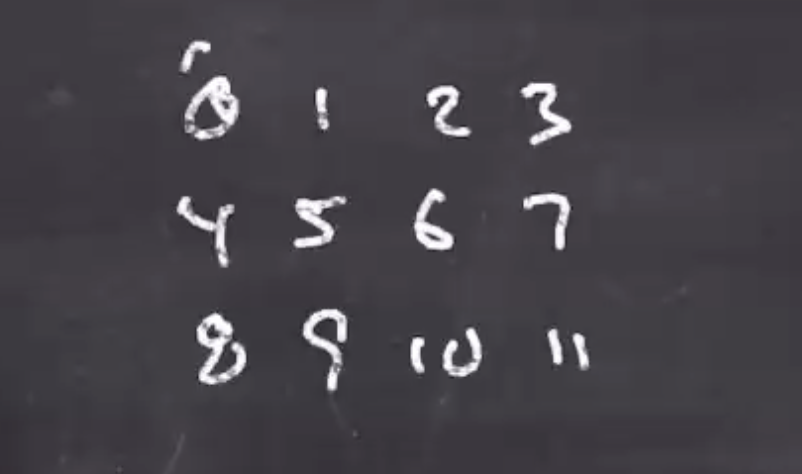
If we think of the 12 values as a matrix, we scramble them columnwise
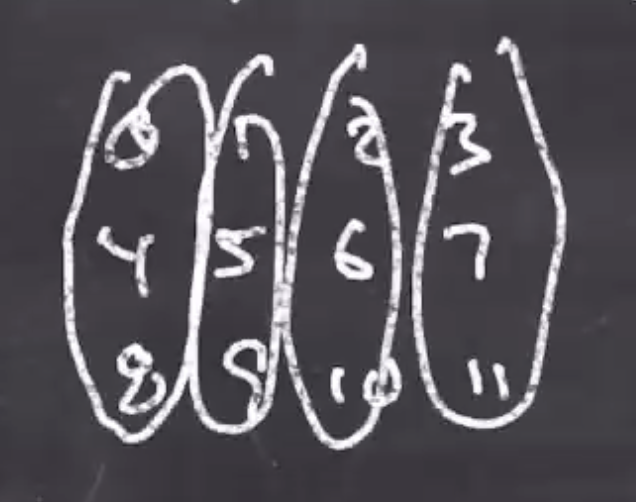
Each column being scrambled are only being scrambled with themselves, so they can be done in parallel. This is where SIMD comes in, we can have a single wide register and think of it as our partitioned data. Then we can do the entire scramble in 1 instruction.
Intel intrinsics documentation
If we consider add_epi16(a, b):

scramble using SSE instructions
#
Lets change this so that it scrambles all 4 values at once.
#include <stdint.h>
#include <immintrin.h>
void scramble(__m128i *a, __m128i *b, __m128i *c)
{
// read
__m128i ssex = _mm_loadu_si128(a);
__m128i ssey = _mm_loadu_si128(b);
__m128i ssez = _mm_loadu_si128(c);
// rotate
ssex = _mm_or_si128(_mm_slli_epi32(ssex, 24), _mm_srli_epi32(ssex, 8));
ssey = _mm_or_si128(_mm_slli_epi32(ssey, 9), _mm_srli_epi32(ssey, 23));
// scramble
// *a = z ^ y ^ ((x & y) << 3);
_mm_storeu_si128(_mm_or_si128(ssez, _mm_xor_si128(ssey, _mm_slli_epi32(_mm_and_si128(sses, ssez)))));
// left to reader...
// *b = y ^ x ^ ((x | z) << 1);
// *c = x ^ (z << 1) ^ ((y & z) << 2);
}

While the amount of instructions isn’t less when using SSE (its actually a few more), it is doing the entire scramble process in parallel.
File reading/writing in C recap #
Recap on reading/writing files in C


A useful pattern:

