Compiler front end #
Compilers are presented with source code, and that goes through the front end of the compiler. This front end builds a parse tree and sends that to the back end of the compiler. The back end produces an executable.

The front end is composed of multiple steps
- Lexical analysis, sometimes called the scanner. This takes the source code and produces tokens.
- Syntactic analysis, called a parser. The parser consumes the tokens and produces a parse tree.
- Semantic analysis. This produces an annotated parse tree. This is stuff like type checking.
Everything in the front end is CPU independent. All it cares about is what language you are in. There is 1 front end per programming language.
The back end of the compiler takes a tree and goes through a code generator. This then passes through an optimizer, and then is passed into the final code generation.
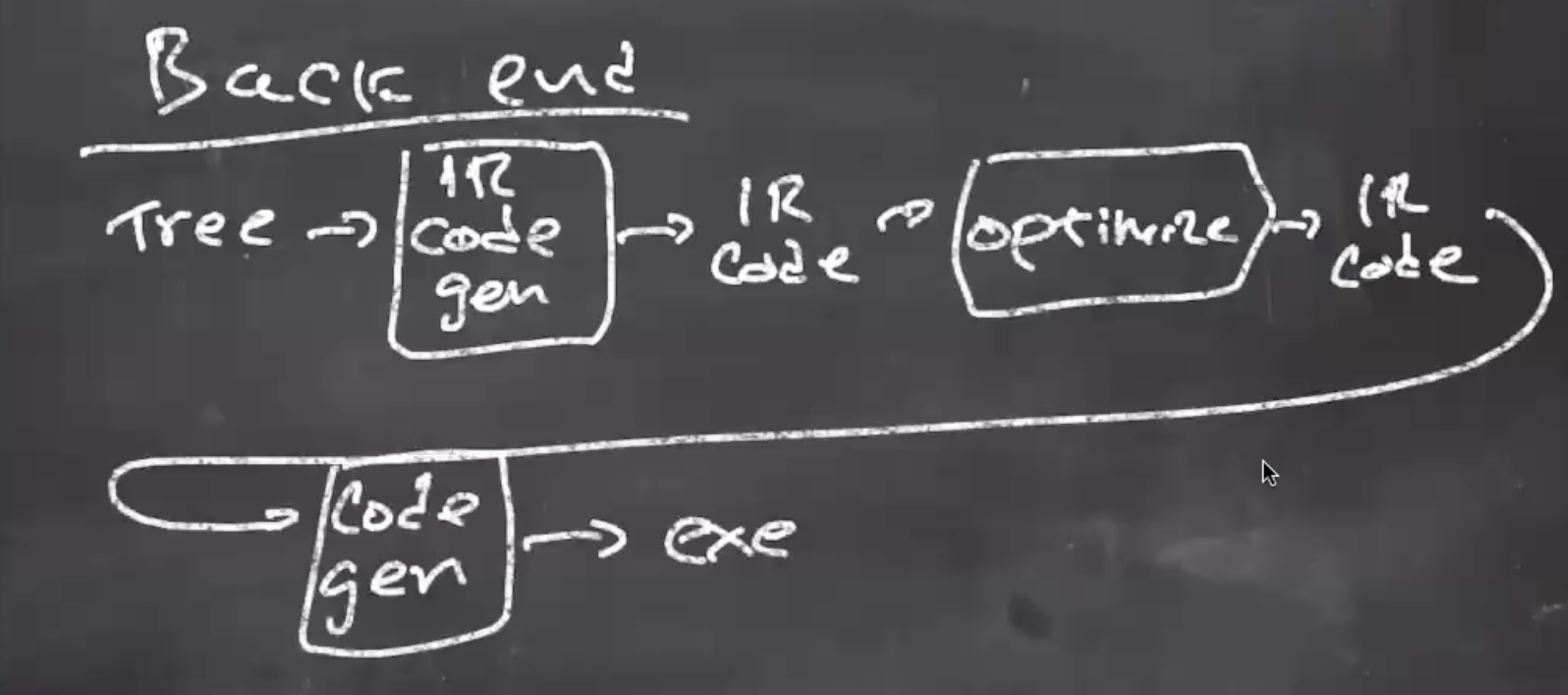
IR = intermediate representation, code that isn’t in a CPU’s language yet.
You only need 1 code generator per CPU. By taking 1 front end and 1 back end, you can have a compiler that compiles a specific language for a specific CPU.
Lexical analysis / scanner #
The scanner takes in source code, and skips all the meaningless stuff in the source code and focuses on the chunks of your program.
For example
// a comment
if (x == y)
{
x = -x;
}
The parts of this code that is important is the keywords, the variables, the operators, and the grouping elements. Things that are not important are whitespace and comments.
The scanner takes this and turns it into a sequence of tokens.
"if", "(", "x", "==", ...
Interface to a scanner #
We have 2 essential functions:
next()returns, but does not remove, the next tokenmatch(t), if the next token in the stream ist, then removetfrom the stream, otherwise throw an exception
Scanner behavior #
When we call next(),
- The first thing we do is skip meaningless characters. Here meaningless characters are things like comments and whitespace.
- Then, we find the longest prefix that is a legal token (the principle of longest sub string).
For example if we see
ifelsewe don’t want to stop after seeingif. The scanner will continue as deep as it can to find the longest legal token. Another example of this is the==, which should be the equality operator and not 2 assignment operators. - Subsequent calls to
next()return the found token untilmatch()is called.
When we call match(t),
- if
next() == t, then we removetfrom the input stream, otherwise throw an exception
Where do scanners come from? #
Scanners can be written by hand.
It is possible to completely write both these functions by hand, if the language is simple enough.
These are usually a bunch of if elses that compare the tokens.
For example, gcc is considered an adhoc scanner, and written this way.
The other way to build a scanner is from a scanner generator. The scanner generator is a program that takes in a file, called a lexical specification. This reads the specification, and outputs scanner source code.

This is an automated process to build scanner source code.
Lexical specifications #
The first step is to write down all the rules for tokens. An example format for a specification is
TOKEN_CLASS: regular expression
The regular expression here represents one token. For example for an identifier:
ID: [a-zA-Z][a-zA-Z0-9]*
So for example:
WORD: aa+aaa
OTHER: aa*
So here, next() will skip meaningless chars, and then find the longest prefix that matching a regular expression, it will then return the class and lexem that match.
Since aaa will match both regular expressions, the scanner will return WORD because it is listed first.
The token that is returned will be WORD, "aaa".
So if our input is
a aa aaa aaaa
The whitespace at the beginning will skipped, and the first a will match (because neither of our regular expressions accounts for a space).
So the first token that next() returns will be OTHER, "a".
Once this token is consumed via match(), the next token that next() will return is WORD, "aa" because WORD comes before OTHER.
This continues on through the stream…
Lexical specification to DFA algorithm #
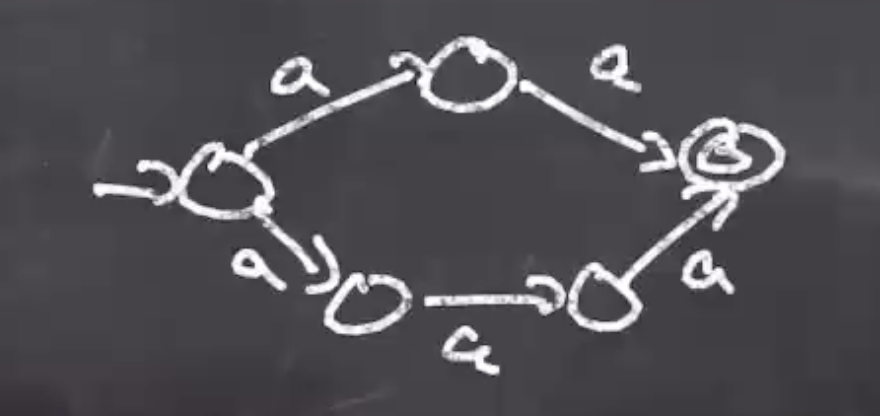
- Use the RE-to-NFA algorithm for each regular expression.
For aa+aaa:
For aa*:
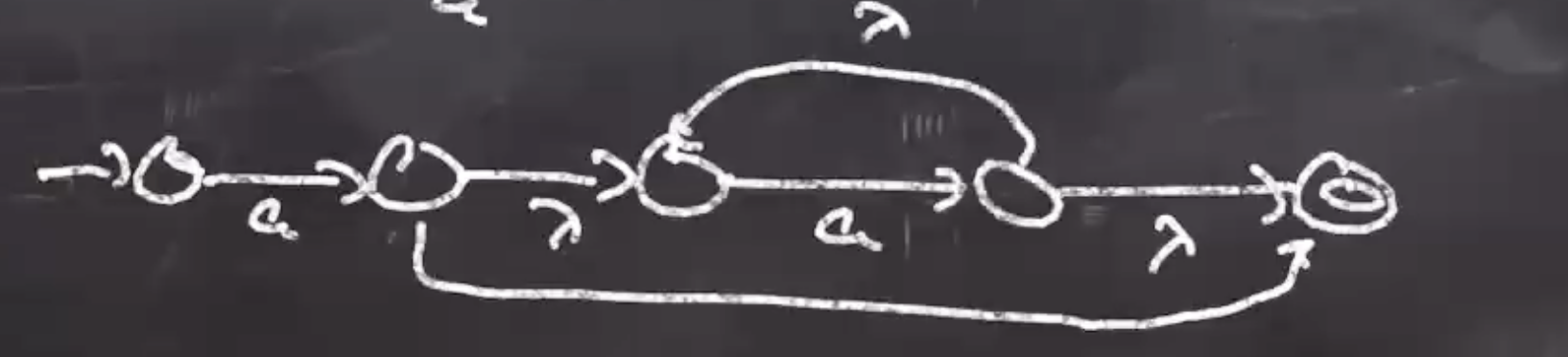
- Make new start state and use \( \lambda \) transitions to all NFA start states.
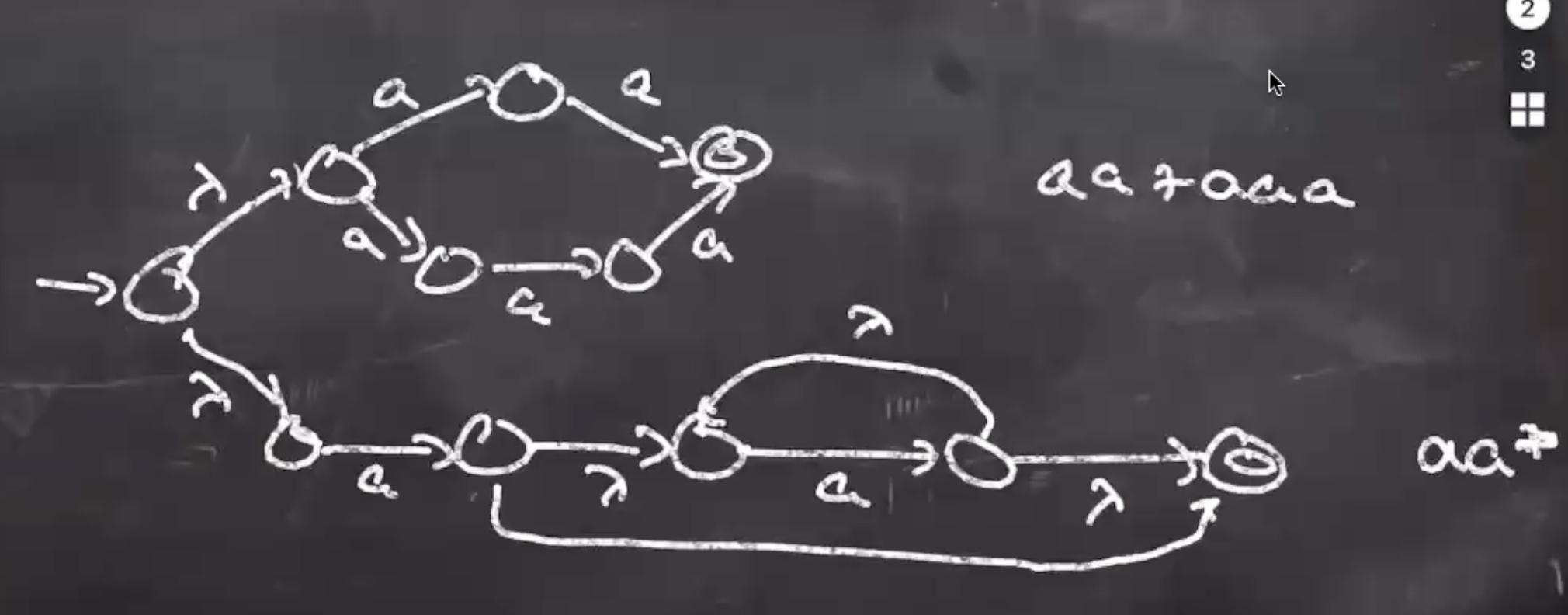
- Use the NFA-to-DFA algorithm to create the scanner.
- Mark each DFA accept state with token class.